
Page 82 - 《中国图书馆学报》2013年第1期
P. 82
献行为是否具有偏好性,具体表现为创建词条行为 用免费爬虫——火车采集器进行数据爬取。 火车
与编辑词条行为之间是否具有很大的差异性。 采集器需要人工编写采集规则.所以首先要对百度
百科的数据形式和网站结构进行研究。
3 研究方法 百度百科的词条按照创建时间升序编排.创
建时间最早的词条“百度百科”是用户“百科万事
3。l 研究对象 通”于2006年 4月5日 l5时37分创建,以数字“l”
考虑到百度百科在国内使用广泛.词条数量 为标记.以此为基点逐渐递增。 百度百科词条页面
大、用户多,以其为研究对象可以更好地反映出中 中存在词条名称、词条内容、词条统计等内容。 本
文环境下的百科词条特征和用户贡献行为特点.针 研究还需要词条编辑的历史信息,这些信息都存在
对现有研究的不足.本文选择百度百科为研究对 于词条所属“历史版本”的页面中,如词条“百度百
象,以大量事实数据为基础,分别研究中文百科词 科”的历史版本页面的网址为“http://baike.baidu.
条增长规律、内容增长规律、词条编辑次数规律以 com/update/id =1”,从中可以看出在百度百科中无
及贡献者行为的规律,并将创建词条行为与编辑词 论是词条主页面网址还是历史版本网址的数字编
条行为分离来分析研究用户贡献行为的特点。 号都是相同的,这为我们的数据采集带来了便利,
与维基百科完全开放不同,百度百科并不提 表 1 是要采集的数据内容及其所对应的正则式。
供词条资料和用户资料的下载服务。 所以,笔者利
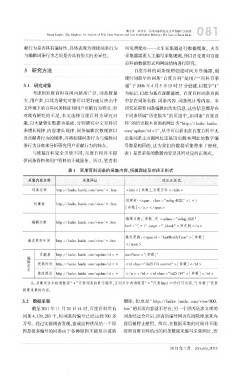
表 l 百度百科词条的采集内容、所属网址及对应正则式
注:采集网址中的通配符“ +”代表词条的 数字编号 ,正则 式中的通配符“ +”代表 html中的任何内容,“[参数]”代表
将要采集的内容。
3i2 数据采集 删除,如地址“http://baike.baidu.com/view/800.
截至2011 年 11 月 24 日 l4时,百度百科共有 htm”的页面内容就不存在;另一个原因是多义项的
词条 4,139,283个,但词条的编号已经达到 700多 词条经过合并后,原有的编号网页在清除掉原来内
万号。 经过实验调查发现,造成这种状况的一个原 容后被停止使用。 所以.在数据采集的时候并不能
因是很多编号的词条由于各种原因不能显示或被 按照百度百科给出的词条数量来编写采集网址.而